AI is one of the major technological shifts of our time. That is exciting, but it can also feel overwhelming. New buzzwords appear all the time, and everyone seems to be moving fast. The hype is real, but so is the pace.
That is why it helps to be grounded in the fundamentals. They stay stable much longer. With that base, you can look at new tools and tell hype apart from facts.
This is exactly what this article is for: giving you a strong footing in the fundamentals of AI.

A video version of this article is available at https://youtu.be/nwkrpyGh4F8
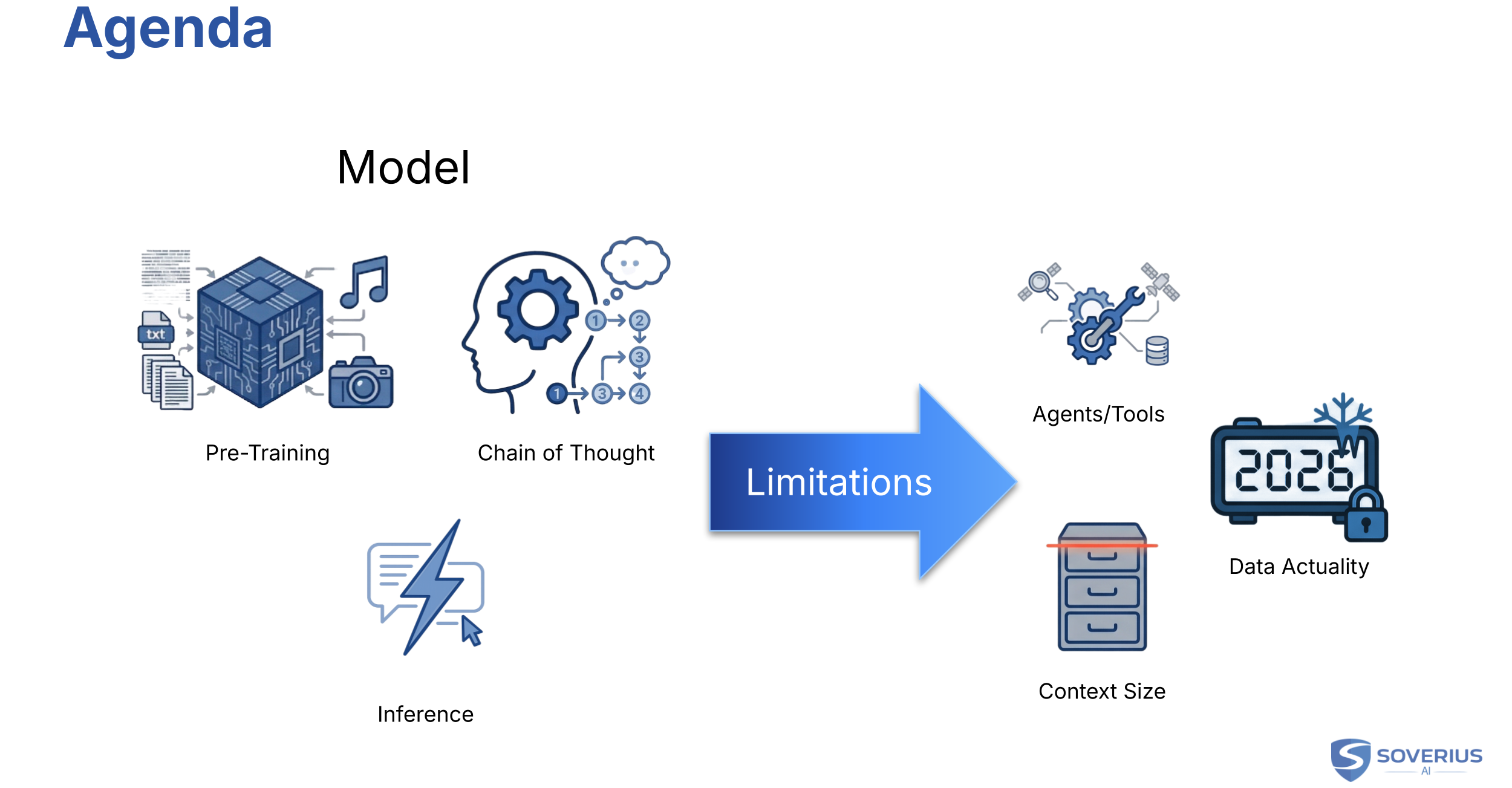
1. Agenda
The core of AI is always the model. So we start with how a model is created — that is, trained. We then build a basic understanding of how the model produces its output, which we call inference. And we also need to understand how "Chain of Thought" works, which is also known as thinking.
Based on these fundamentals, we will also understand the limitations of the models and how different techniques and tools are trying to solve them. In the limitations section we cover:
- Why a model needs agents and tools — and what sits between us and the model.
- The limited context window and how chats, memory, and cost actually work.
- Data actuality: cut-off dates, private knowledge, and ways to supply fresh or internal data.
Disclaimer: The examples are extremely simplified and are only meant to give you a basic understanding of the concepts. The actual processes are much more complex and involve a lot of technical details.
2. The Model
In the world of AI, the core is the model — or more specifically, the Large Language Model (LLM). When you hear people talk about GPT, Claude, or Gemini, they are referring to these models.
2.1 Training
Training is how we create a model. There are multiple phases. The first is the pre-training phase. This is something you will probably never do on your own because it is so resource-intensive in terms of time, data, and computational power. Still, it is important to understand what it is and what a model is capable of after it is pre-trained.
In pre-training, texts are fed to the model. For example:

Since the model needs to do "a few" calculations - sarcasm intended - it has to map the text to numbers. It splits the text into chunks, which we call tokens. A token could be a word, a syllable, or some characters. The list of these tokens is fixed for a given model — we call that list the model's vocabulary.

These tokens are then mapped to numbers, which is what the model uses.

The splits and numeric IDs above are real: they are what GPT-4o's tokenizer produces for the text above.
A few things to highlight here:
- The tokens are language-independent. As we can see, the text contains both German (Österreich, Leoben) and English words.
- The model can also process letter sequences that are not ordinary words. For example, hoby is not an English word (a typo for hobby), but the tokenizer still breaks it into pieces we can see in the colored line above.
- Lower token IDs often go to very frequent pieces. Here, M is 44 and R is 49. Österreich is one token (70,997): a whole placename in one chunk, with a high ID because that piece is rare — unlike everyday bits such as the or and.
- Whitespace and punctuation matter. Period + newline is often one token — here 558 after OGRE and after sees (end of those lines in the sample). The period after Wars is a plain 13. The final period after profession is also 13, because we stopped the sample there with no trailing newline.
2.2 Pre-Training Begins
What happens now is that the model is presented with a token or tokens, and has to predict the next one. For simplicity, assume a token is always a single word.
So the training system would present the first word of the training data, which is "Murat". The model will then start to guess and will provide different tokens/words, like "is", "and", "Star", and so on.
Once the model comes up with "lives", the training system will give it a green light and will continue with the next word afterwards.

So it will ask the model to predict the next word for "Murat lives", which will eventually be "in".

And it will continue like this with test rest:

The training system knows the text and therefore the correct answer. This training process can be fully automated, so no human is needed to tell if each next-token guess is correct. More precisely, this is usually called self-supervised learning: the supervision signal is generated from the text itself. Given that automation, it is extremely scalable. That is why models can be trained with enormous amounts of data, which is one of the key reasons for the success of AI.
2.3 How the Model Learns
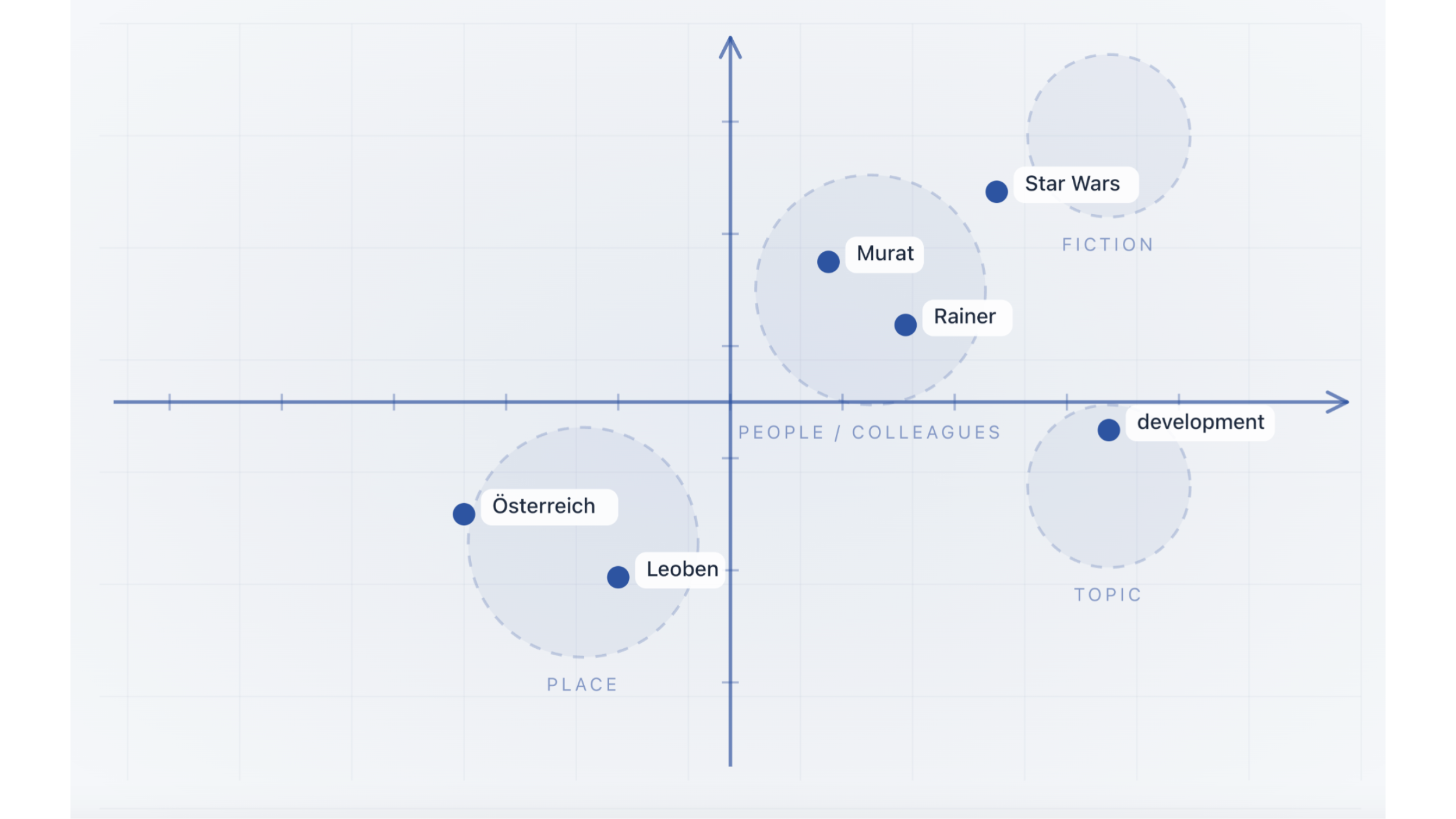
Over time, the model starts to discover patterns internally. For example, it will "learn" that Murat and Rainer are quite similar. For humans, that is obvious because they are both names. But the model discovers that over time and through endless loops.
Based on those groups — call them dimensions — the model will then also start to recognize patterns in how they are used together in sentences. And that's key. Because the more patterns the model learns, the higher the probability that it will be able to predict the next words correctly.
2.4 Inference
This process where the model returns the next token is called inference. Inference runs during training to score whether the model's prediction was correct. It is also what we as end users rely on once the model is deployed and we start to interact with it. So whenever we ask ChatGPT a question, the process of giving an answer is inference.
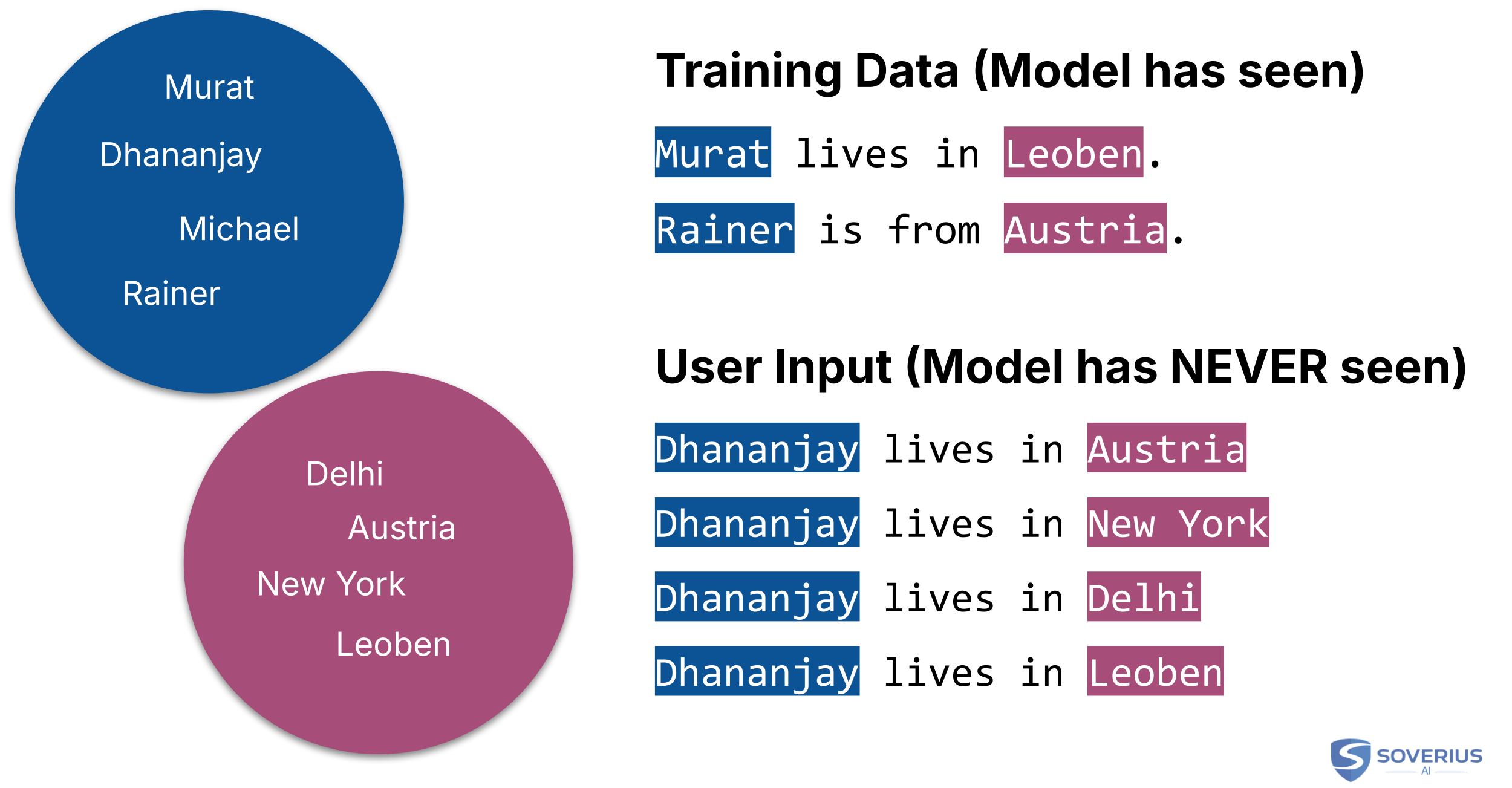
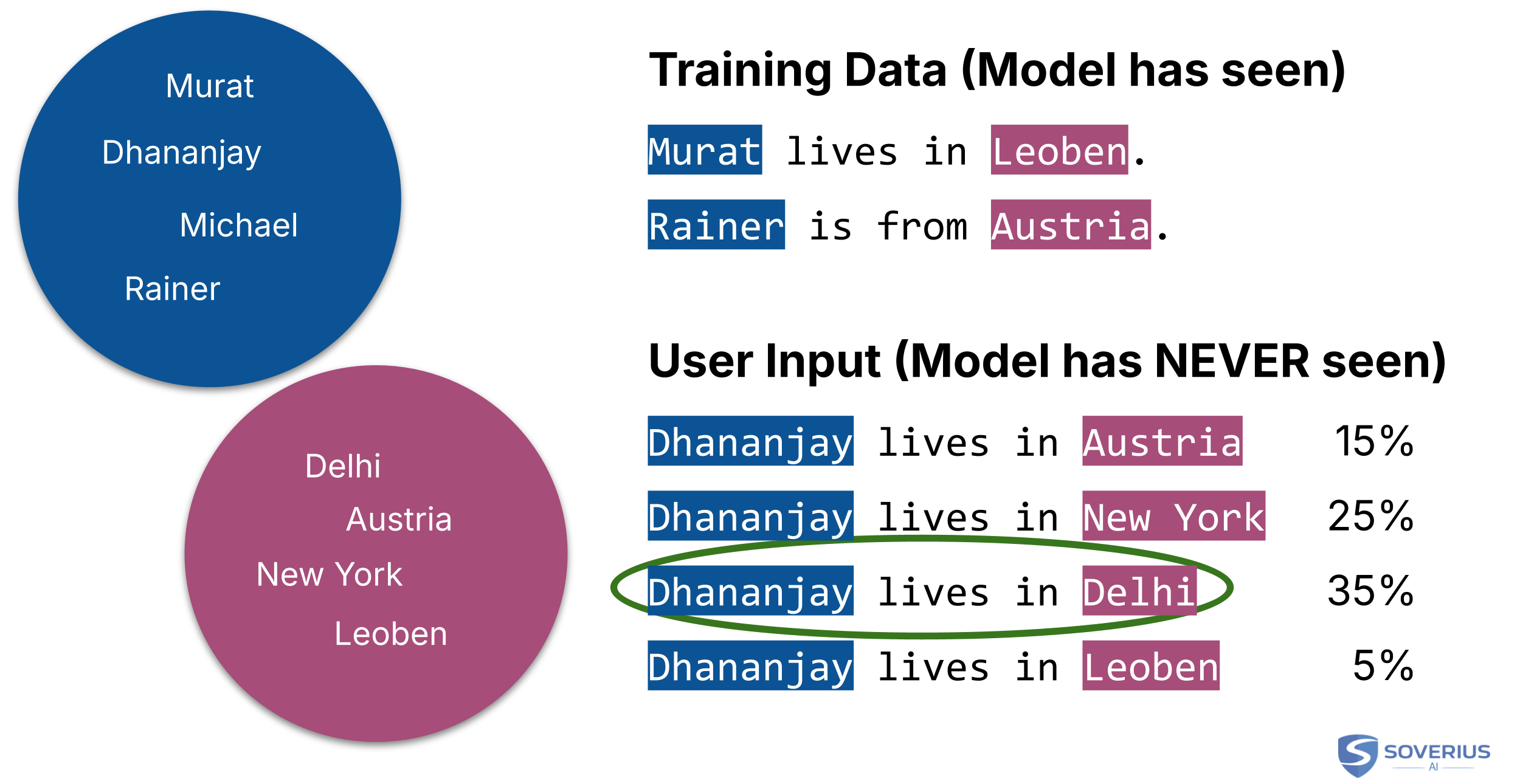
Let's take an example. The model's training data contains the following sentences:
- Murat lives in Leoben.
- Rainer lives in Austria.
During training, the model is presented with a sentence it has never seen before. For example:
- Dhananjya lives in ...
The model should now predict the next word. Via its training, it has learned that the terms "Murat", "Rainer", but also "Dhananjay" have a certain similarity ("Name Dimension"). It has also identified another group, where the following words are quite similar: "Delhi", "Austria", "New York", "Leoben". Let's call that one the "Location Dimension".
This is true for other words as well, but in the end, it would recognize the pattern "Dhananjay lives in" and would now predict that the next word is likely to come from the "Location Dimension".
So the model would come up with the following potential predictions:
The model has to choose one of the many choices. To do that, it has to apply probabilities to each word. How does that work?
There are of course a lot of other dimensions available. For example, we could have dimensions which would represent certain cultures or regions. There could be a German dimension, which contains words like "Leoben", "Austria", "Rainer". And there could be an Indian dimension, which contains words like "Dhananjay", "Delhi", "Vishnu", and so on.
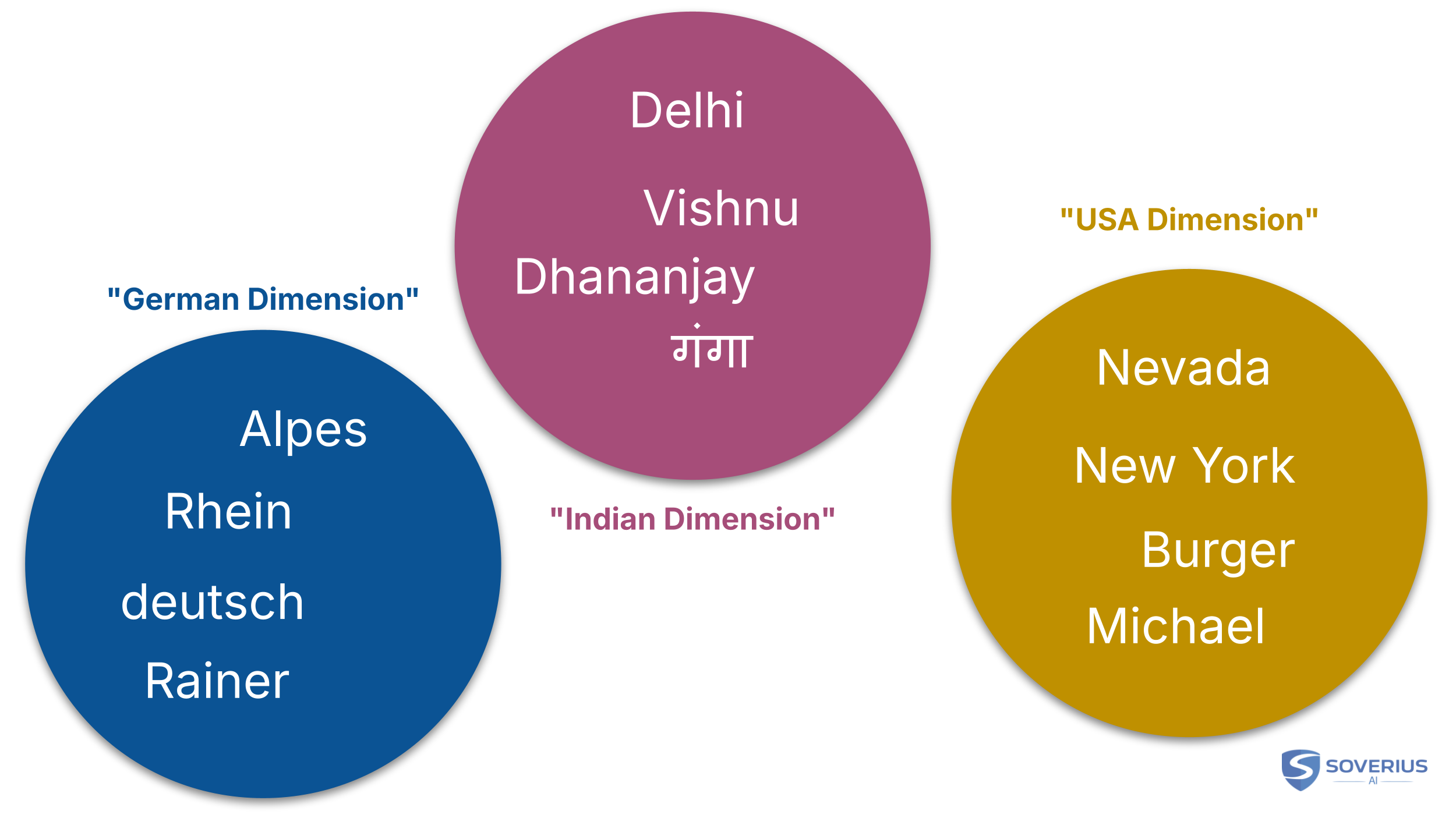
The model would see that "Dhananjay" and "Delhi" have the strongest connection. It would therefore assign the highest probability to "Delhi":
By now, it should be obvious that a model "does not understand" text. Instead, the model is a huge prediction machine which is solely based on patterns and probabilities.
It should also be clear that the model is not a simple lookup table. It can predict words in sentences it has never seen before. On the flip side, this also addresses certain myths. For example, if we type in our credit card number and the model is trained on it, some fear it would give us the credit card number back if we ask. While there is a tiny probability it could do that, the chances are very low.
In real life, models also have guards which jump in if we ask for something that is not appropriate. For obvious reasons, the training data itself is also filtered. So there are a lot of guard rails, and those myths stay what they are: myths.
2.5 Temperature and Hallucination
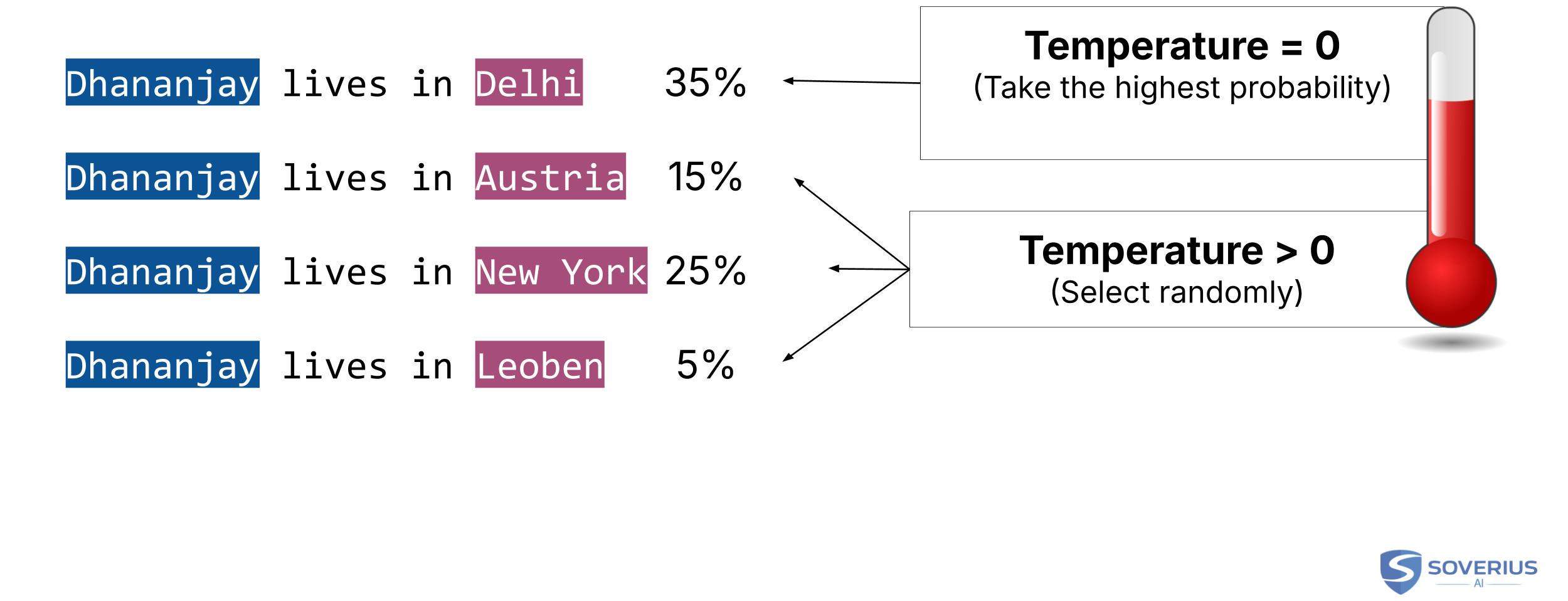
As we might have noticed, we did not explicitly say that the model will always choose "Delhi" as the next word. It has the highest probability, but that does not mean it is the only choice.
Temperature is a parameter that controls how random the output should be. Lower values make the model more focused and deterministic. Higher values make it sample more broadly from plausible next tokens.
This introduces randomness into the output. Depending on the task, that can be good or bad.
If our demand is fact-driven — for example, there is only one right answer — then we usually prefer a temperature close to 0. If we want creative output, like writing a poem, we prefer a higher temperature. A higher temperature allows the model to explore more possibilities.
An accompanying term to temperature is hallucination. This happens when the predicted word is incorrect, though the definition is a bit relative. What does "incorrect" mean in this context?
If there is no clear answer and we want creativity, we want the model to come up with new things. In that case, it is a "desired hallucination." On the other hand, if we wanted facts and the model invented false details, we call that a hallucination — not creativity. So the term depends on the context, but it usually has a negative connotation.
My takeaway here: the model does not lie in the human sense. Hallucinations can happen for many reasons: weak or missing knowledge, ambiguous prompts, sampling choices, or other technical limitations. A high temperature can make them more likely, but it is not the only cause.
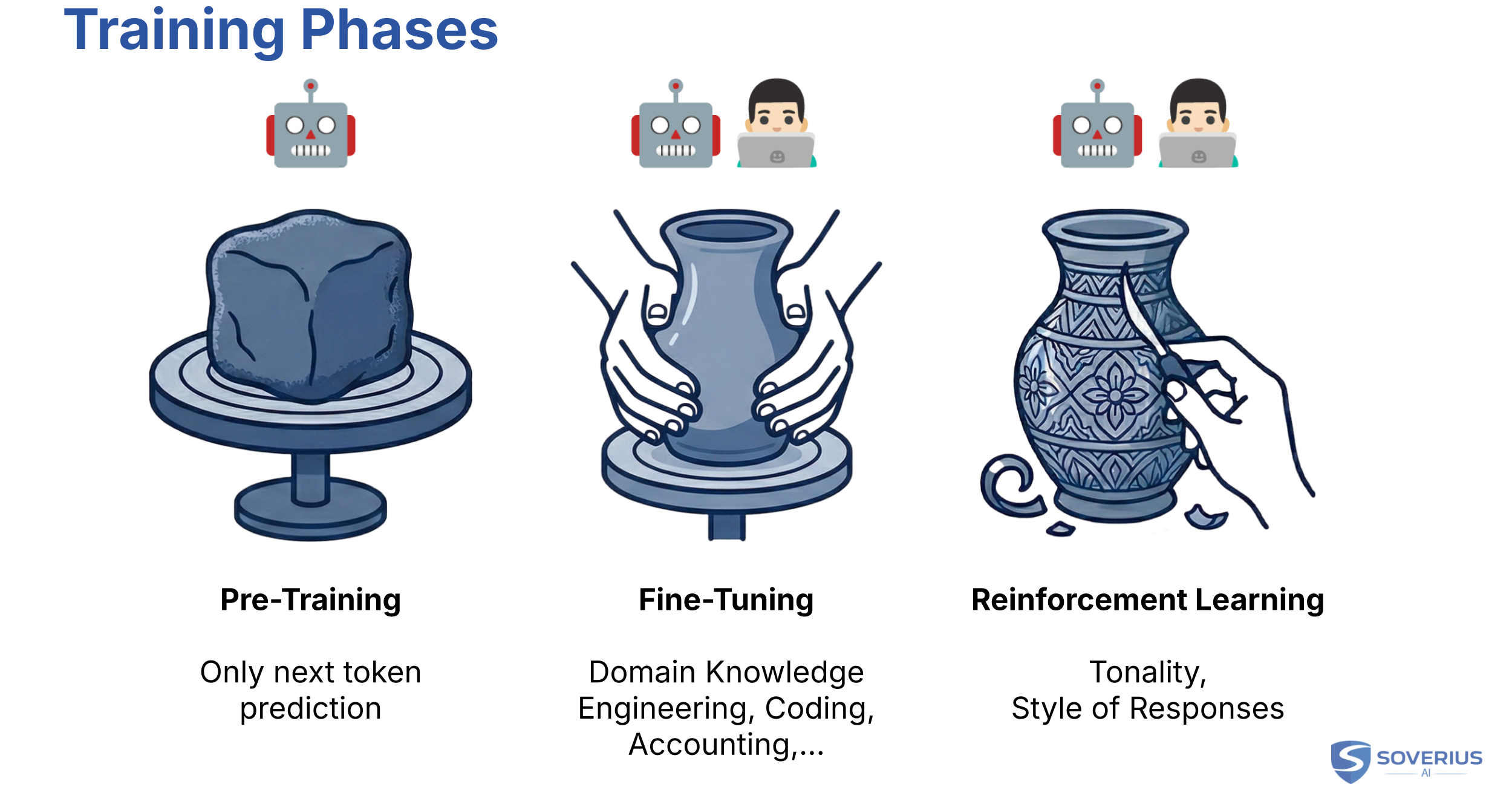
2.6 Training Phases
Until now, we have only discussed the pre-training phase. Logically, there must be a post-training phase as well. The naming is not quite as logical: the main phases that follow pre-training are fine-tuning and reinforcement learning.
Once pre-training is done, the model has learned enough patterns to process human language by predicting the next word. But this is not the end. Although the model has a lot of knowledge, it lacks domain-specific expertise.
For example, we might want a model specialized in history, engineering, medicine, or company-specific data. This is where fine-tuning comes in. It can adapt the model to a domain, a style, or a task. But the broad knowledge of frontier models mostly comes from pre-training, not from fine-tuning alone.
In the classic case of supervised fine-tuning, we provide examples of good outputs for given prompts. Those examples are often created or reviewed by humans, and AI can also help prepare or check them.
After fine-tuning, reinforcement learning (often RLHF, Reinforcement Learning from Human Feedback) shapes the model's unique style or tonality. Think of it as the model's "character." Like fine-tuning, this phase is partially supervised, and human preference data matters a lot.
It is important to understand that pre-training can happen in a fully automated, self-supervised way. No human needs to label each example, which means we can scale it to enormous amounts of data. That automation is one of the breakthrough factors behind the success of AI.
In practice, most of us would only work with fine-tuning or reinforcement learning ourselves. The resources required for pre-training are so high that it is left to a few major companies. We can use their pre-trained models for free or via API. Fine-tuning and reinforcement learning are things we can do on our own. Even then, they are still substantial efforts, so we usually only reach for them if easier techniques — like RAG or In-Context Learning — do not solve the problem. We will briefly cover those later.
2.7 Chain of Thought (Thinking)
For our purposes, we mostly use the term chain of thought (CoT). You will see the same idea called thinking in product UIs, or reasoning in other articles. These are not always exact synonyms, but they belong to the same family: intermediate work before the final answer.
You have likely seen videos where people ask top models simple questions like "How many 'r's are in strawberry?" and the model gives the wrong answer.
That is becoming outdated. You would have to go back to the early days of AI to replicate that easily, but there is some truth in it. As we've seen, the model does pattern matching. If it has to solve a mathematical problem, that pattern matching can become "educated guessing." The model doesn't actually count the letters or calculate equations in the traditional sense.
Still, that problem can often be handled elegantly. When we ask a model a question, it can turn "inwards." It reformulates the question into: "What steps would I take to answer this?"
The output is not always the immediate answer, but intermediate reasoning about how to solve the problem.
The trick is simple. Instructions fit the pattern matching of a model much better. There are countless patterns for solving equations, which suits the model's behavior.
Chain of Thought is the technique where the model reflects on the question first and then works through a solution. This is why it is called thinking. Be aware that this comes at a cost. It usually takes longer to get an answer, and reasoning models may consume additional reasoning tokens, which increases cost.
Below, you find an example of how a model infers the square root of the number 4:
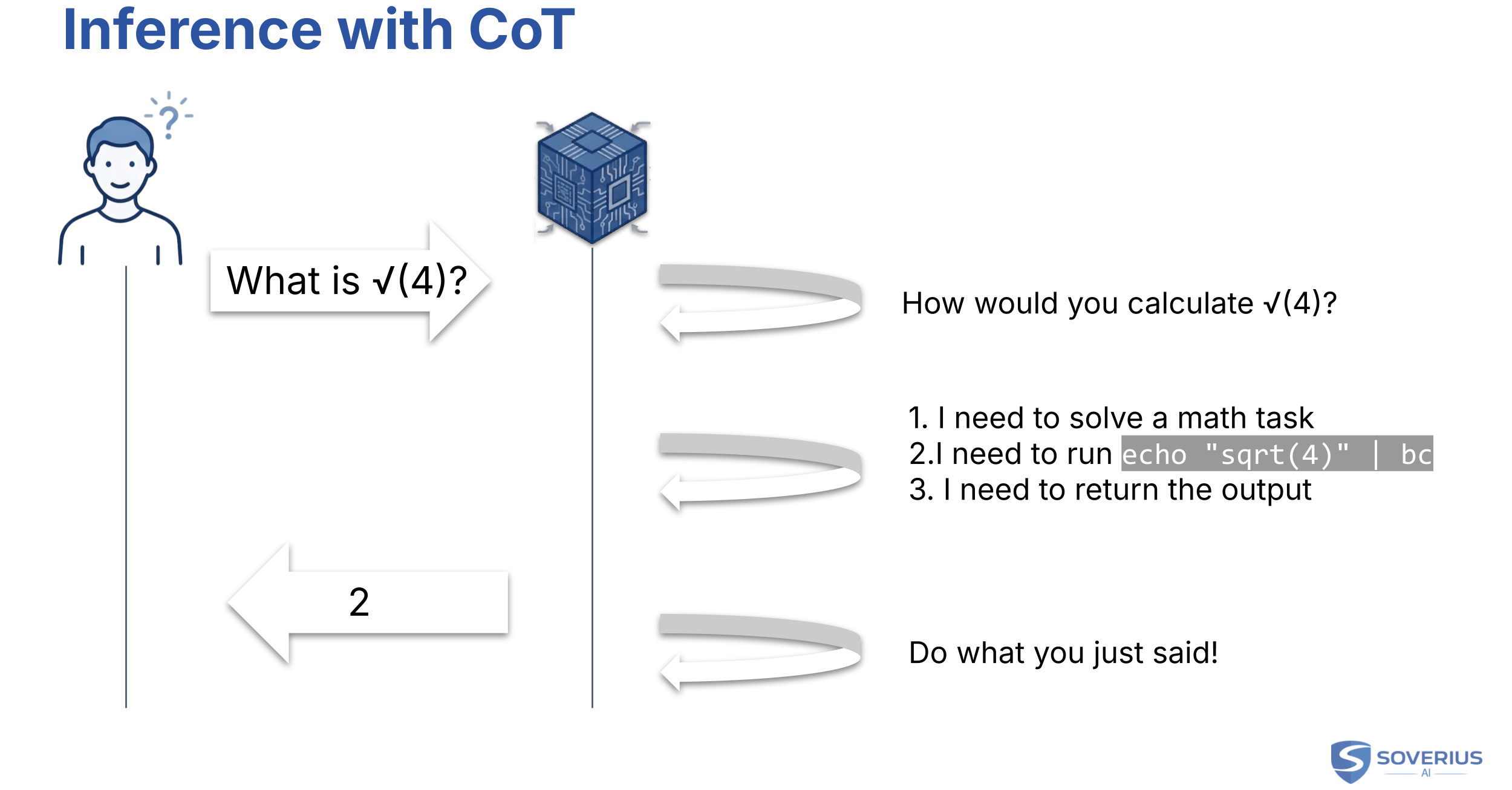
Chain-of-thought behavior is largely shaped during fine-tuning and reinforcement learning.
This intermediate reasoning is still only text inside the model's process. How that later connects to actions in the outside world is a separate topic, and we cover that next.
3. The Model's Limitations
Based on what we have covered, the model is a massive pattern-recognition machine. It takes text in and puts text out based on learned patterns. That's it.
If we compare this to the capabilities of modern AI — like producing code, fetching info from the internet, or making reservations — there is a huge gap.
The following sections connect that gap to how we actually use AI: agents and tools, context and memory, and keeping knowledge fresh.
In short: the model has a maximum amount of text it can process at once. Quality often drops well before you hit that limit. Its baked-in knowledge has a cut-off date and misses private data. And on its own, the model only emits text. Anything that looks like "doing things in the world" happens through agents, tools, and the systems built around the model.
3.1 Agents & Tools
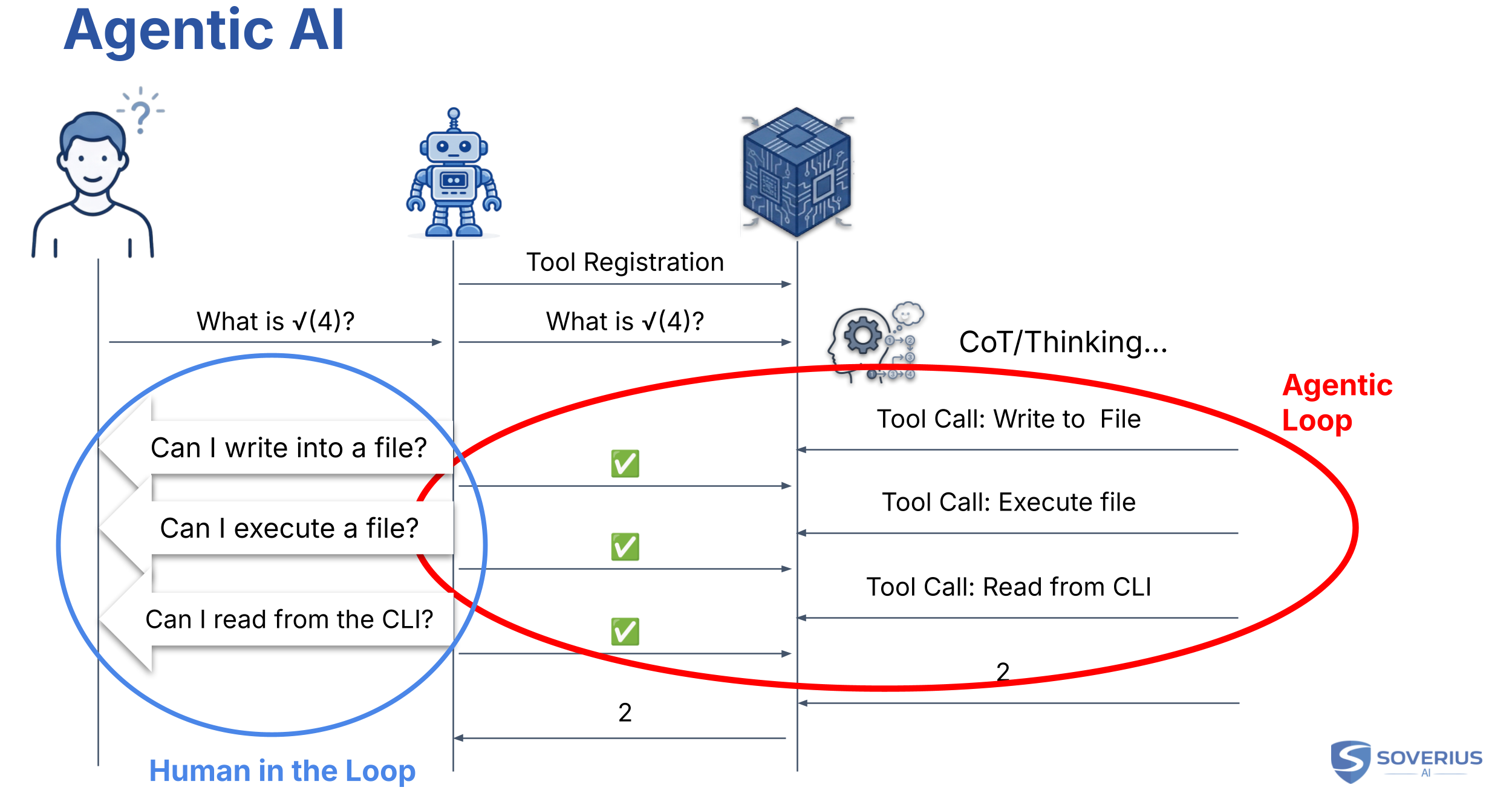
Let's return to the CoT example where the model came up with instructions to run a script. The model itself is not allowed to do that. Instead, we have a mediator between the user and the model, which we call the agent.
The agent receives our messages and forwards them to the model. But there is a key first step: the agent "introduces" itself.
It tells the model about certain tasks it can perform if instructed. These might include writing to the file system, executing code, or reading from the console. This is exactly what the model needs to calculate a math problem accurately. The model becomes aware of the agent's "tools."
When the model performs CoT, it includes this portfolio of available tools in its plan. Once the plan is ready, the model instructs the agent to call a tool on its behalf. In this sense, the term "agent" matches its usual definition: it acts on behalf of someone else. Here, that "someone else" is the model plus the product's safety rules.
After the tool call is complete, the model continues to instruct the agent to execute the next steps. This is an ongoing communication where the end user is not directly involved. We call this the "Agentic Loop." Once the model has the final answer, the agent returns it to the user.
For obvious reasons, an agent should not be allowed to perform dangerous actions whenever it wants. It should get approval from the end user first. Usually, when the model requests a tool call, the agent will ask the user for permission. This is what we call the "Human in the Loop."
As a side note: agents are just software, so they cannot perform physical actions in the real world. But from the model's perspective, the pattern can look very similar. If a user told a model it could order food, the model might emit instructions aimed at a human operator instead. Services like Rent a Human show how blurry that boundary can become.
Model Context Protocol (MCP) is a common way to expose tools to agents. In 2025, it gained attention as a standard format for tools. In 2026, we also hear about Agent Skills and patterns that keep tool metadata out of the context window until it is needed. The landscape moves quickly, but the underlying problem — connecting models to capabilities without bloating the context window — remains the same.
3.2 Context Management
A model receives input and produces output. The proper term for that input is the context. The context window is limited. Current frontier models, such as GPT-5.4, advertise up to 1M tokens of context. Crucially, the model itself is stateless. On its own, it does not remember earlier messages.
Let that sink in. Stateless? No memory? That does not match how we experience ChatGPT. So what gives?
If we introduce ourselves to ChatGPT, it remembers our name throughout the conversation. It feels stateful because the agent is managing the memory.
The agent feeds not just your current prompt, but the complete conversation history back into the model. The model can refer to previous points only because it is being re-fed the entire story every time.
Modern chats can even remember things from months ago. Vendors call this "memory." But the important point remains: the model does not have a memory. The agent around it does the work to make it look that way.
How does the agent do this? It stores the history in a database. It lets the model know about the database and the potential to load data from it. This is another tool the model can use.
A common technique is called RAG (Retrieval-Augmented Generation), which can also be used to load internal documents or other data. The challenge is finding the right data without overloading the context. For more on RAG, see our free e-book.
Context management also has a financial aspect. We pay for the number of tokens we use. Output is typically more expensive.
Based on OpenAI's standard rates for GPT-5.4 (as of 2026-04-21), requests in the standard context tier are priced at 15.00 per 1M output tokens.
As a rule of thumb, 100 tokens is roughly 75 English words. If you feed the model 1,000 words:
1,000 words × (100 tokens / 75 words) ≈ 1,333 tokens
1,333 tokens × (0.00333
The price for the input would be around $0.0033. If the model writes an article of 1,000 words, the price is multiplied by six — roughly 2 cents.
Because the model is stateless, each follow-up resends the growing conversation history. Input costs add up across turns.
Vendors help reduce costs with prompt caching. Repeated prefixes (system prompts, long documents) can be billed at a lower rate.
What happens if the context window is exceeded? For the model, that would be the end. But the agent can rescue the situation by automatically compressing the input and opening a new window.
As with any compression, some information is lost. How much quality remains depends on the agent's strategy.
Compression can start even earlier. It is usually not a good idea to maximize the context window. If the context gets too large, the quality of the output can decrease. Studies show that models focus more on what was said at the beginning and the end — much like humans do in long conversations.
As users, we can help the model by splitting long tasks into shorter, independent ones. Agents usually show current context consumption. If it becomes too large, we can start a new session.
As a rule of thumb, quality often starts to decrease when we reach about 25% of the context window.
Common terms in this space include:
We can expect context management to become more automated through techniques like Agent Skills.
Another approach is to distribute a task to multiple agents. They might run sequentially or in parallel, often structured hierarchically. An orchestrator agent at the top delegates tasks to sub-agents, each with its own focused context window.
MCP-heavy setups often register many tools up front. This can bloat the context before the user types much. Agent Skills are still tool calls from the model's perspective, but they expose a short catalog first and load the heavy instructions only when needed.
Once the model selects a skill, the full skill text may be loaded into context. That can still be expensive, but the cost is deferred until it is relevant. If a skill triggers a script, it is effectively the same pattern as an MCP tool call: the model requests an action, and the runtime executes deterministic code.
Agent Skills can be lazy-loaded text or real tool calls. MCP is usually eager tool registration.
3.3 Data Actuality
Models are trained on vast amounts of data, but once the training is done, they are not updated in real time. Events that happen after the "cut-off date" are simply unknown to the model.
A model might also lack access to private or internal data. If you want it to support internal processes, it must be aware of your specific rules and regulations.
One practical approach is simply copying necessary data into the context window. This is called In-Context Learning. It is the easiest method and works well for simple tasks, like summarizing a research paper or uploading a manual. Terms like "Few-Shot Prompting" or "Zero-Shot Prompting" are related to this.
A more sophisticated approach is RAG. With RAG, we use a vector database. The model requests relevant data via a tool call, and the agent identifies the best information to feed back into the context. Again, for a deep dive, check out our free e-book.
Finally, a general tool call — like a web search — is a common way to get data from the outside world.
I hope this gave you a clearer view of the fundamentals behind modern AI. Questions? Email info@soverius.ai. For new essays and workshop announcements, use the "Stay Updated" form.

The Enterprise AI Architect Workshop (3 Days) · 3 Days
If you want to dive deeper, our workshop AI Architecture for Enterprises (3 Days) is a practical starting point.
Comments
No comments yet. Be the first.