
A2UI is a protocol for agent-driven user interfaces, and gets more and more attention. A2UI was created by Google and published in 2025, and the current draft is the v0.9 release.
The core idea is simple. We need a JSON specification that describes how to construct user interfaces and interact with them on the client. The specification consists of a so-called catalog which describes the supported functions, theme, and components (for example a text component with its supported properties). To make our life easier, Google provided a basic catalog to get started.
We see three approaches in the area of dynamic UI and AI.
Controlled Generative UI is what we used in our Sheriff talk at AI Poland. We hand-built concrete UI components for our specific use case, and the subagent's system prompt described what was available. The LLM just selected the right component and transferred it as a structured object to the client. Narrow surface, predictable output, no surprises.
Declarative Generative UI is where A2UI sits. Instead of a fixed catalog for one use case, you give the LLM a general-purpose set of primitives (text, columns, buttons, forms) and let it compose UIs from those building blocks. It is closer to a meta UI framework written in JSON: the model is no longer picking from a menu, it is laying out a tree. A2UI specifies both the JSON schemas and a way to build the UI incrementally during inference, which Google calls "Progressive Rendering". The LLM generates the JSON specification for the user interface, and we render it on the client.
Open Generative UI is the most permissive of the three: an iframe renders fully generated code such as HTML and JS. This has potential and gives the LLM full freedom, but it is hard to reason about UX, and inference can take a long time.
What A2UI is
A2UI has seven distinct surfaces.
The versioned spec is a JSON Schema document plus a basic component catalog, distributed in specification/v0_9/. Agent output must validate against this schema or the client refuses to render the surface.
The message protocol defines four message types: createSurface, updateComponents, updateDataModel, deleteSurface.
The trusted-component-catalog handshake lets the client advertise supportedCatalogIds in metadata. The agent selects from that list and locks the catalog for the lifetime of the surface. The security argument depends on this handshake: the agent can only request components from a list the client pre-approved.
The four-layer validator stack lives at agent_sdks/python/src/a2ui/schema/validator.py. The layers are a JSON Schema Draft 2020-12 validator, an integrity check (unique IDs, root exists, references resolve), a topology check (no cycles, no orphans), and a recursion limit (global depth 50, function-call depth 5).
The streaming parser and payload fixer are at agent_sdks/python/src/a2ui/parser/payload_fixer.py. The fixer documents what the spec authors expect from a model:
def _normalize_smart_quotes(json_str: str) -> str: return (json_str.replace("“", '"').replace("”", '"')...)def _remove_trailing_commas(json_str: str) -> str: fixed_json = re.sub(r",(?=\s*[\]}])", "", json_str)The fixer normalises curly quotes from LLM output and strips trailing commas before closing brackets.
The reference renderers ship under renderers/: Lit, Angular, Flutter, React, plus community ports. They all consume the same JSON and map it to native components.
The data-binding grammar is a relaxed JSON Pointer (amusing to see a web spec reach for a pointer abstraction) that lets components bind to paths inside the data model. Relative paths are allowed inside templates, and absolute paths begin with /.
Coarse-grained UI spec
It somehow reminded me of WPF, which is also coarse-grained and has its own definition language called XAML. Here is an example:
<!-- MainWindow.xaml --><Window xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" x:Class="MyApp.MainWindow" Title="Welcome" Height="200" Width="320"> <StackPanel Margin="20"> <TextBlock Text="Welcome to the app" FontSize="24" Margin="0,0,0,10"/> <Button Content="Get Started" Click="OnGetStartedClick" Padding="10,5"/> </StackPanel></Window>In XAML we define the full file with the right nesting. In A2UI the definition is more message-based. Basically I can send a createSurface and then send the components incrementally as JSONL for progressive rendering:
<a2ui-json>{ "createSurface": { "version": "v0.9", "surfaceId": "welcome", "catalogId": "basic" }}</a2ui-json><a2ui-json>{ "updateComponents": { "version": "v0.9", "surfaceId": "welcome", "root": "root", "components": [ { "id": "root", "component": "Column", "children": ["heading", "cta"] }, { "id": "heading", "component": "Text", "variant": "h1", "content": "Welcome to the app" }, { "id": "cta", "component": "Button", "variant": "primary", "action": { "function": "openUrl", "args": { "url": "/get-started" } }, "children": ["cta_label"] }, { "id": "cta_label", "component": "Text", "content": "Get Started" } ] }}</a2ui-json>Why does it remind me of WPF? WPF showed me how this can go: looks great, single vendor, slow burn out. I will come back to whether A2UI is set up to avoid that at the end of the post.
But how do they know?
A primary concern with this specification is the knowledge gap: how does the LLM learn to use it? If you are using an internal or a proprietary A2UI catalog, the model - no matter how advanced - has never been trained on your specific UI components.
Because there are no specialized "A2UI-native" models yet, we rely on In-Context Learning (ICL). The entire component catalog must be loaded into the system prompt as a reference. This effectively "pollutes" the context window, consuming a massive amount of tokens just to define the UI's capabilities. This overhead could directly lead to context rot. The model's reasoning is sidelined or weakened by the sheer volume of data.
There are also circumstances where we are not able or allowed to use frontier models (you know, chat leaks and so on). So, does it run with my local models? For that I built an A2UI eval set (~80 prompts, 73 of which are in this run) and pushed it through several machines and models.
The benchmark
Each model was evaluated through the following pipeline:
- Model serving: llama.cpp or vLLM starts an OpenAI-compatible API server with the model.
- System prompt injection: the full A2UI v0.9 JSON Schema and component catalog are injected as a system prompt (~8,000 tokens).
- Generation: the model generates structured JSON output for each evaluation prompt in a single-turn setting. One user prompt yields one assistant response, with no follow-up turns, no self-correction loop, and no schema-error retries.
- Schema validation: programmatic validation against the A2UI schema and integrity rules.
- Semantic grading: an external judge (Claude Code, human-supervised) assigns C/P/I per sample.
- C (Correct): the response satisfies the target. Optional or cosmetic additions and ID/label variations are accepted.
- P (Partial): the response is substantively right but has minor variations (for example, wrong wrapper format around correct components, slight punctuation differences).
- I (Incorrect): the response is missing required components or has substantive errors (wrong variant, missing fields, broken structure, fabricated component names).
The rubric is the same one used by the production Inspect-AI grader (A2UI/eval/tasks.py:GRADER_INSTRUCTIONS). Variations in capitalisation, punctuation, component IDs, label synonyms, and data-binding paths are explicitly allowed.
Setup
- Hardware: NVIDIA DGX Spark (GB10 Blackwell, 122 GiB unified memory, aarch64).
- Inference: llama.cpp and vLLM, every model run on both engines where possible.
- Harness: Inspect AI.
- Spec under test: A2UI v0.9.
- Test corpus: 73 evaluation prompts from
eval/datasets/v0_9_prompts.yaml, covering text, images, forms, lists, modals, dashboards, and nested layouts. - System prompt size: ~8,700 tokens (the full JSON Schema plus the basic component catalog).
- Models tested: 14 model/engine configurations across Llama 3.1 8B, Llama 3.2 1B, Qwen 3 (1.7B, 8B, 14B), Qwen3 30B MoE NVFP4, Nemotron 3 Nano 30B, and Gemma 4 26B MoE (NVFP4).
- Grading: an external judge (Claude Code, human-supervised) assigns C/P/I per sample.
- Full report: A2UI Multi-Model Benchmark Report (Soverius AI internal, May 12, 2026).
Why local models and local hardware
Three reasons.
First, reproducibility. Cloud models are versioned by the vendor without notice. OpenAI updates gpt-5.1 without pinning. Gemini preview tags swap endpoints. Anthropic snapshots are deprecated on a published schedule. A benchmark that runs against any of them today may produce different numbers next quarter against the same name. Local quantised models pinned to a specific GGUF hash or vLLM checkpoint are fixed artefacts. A reader can re-run this experiment six months later against the same weights and get comparable numbers.
Second, deployment relevance. The behaviour of GPT-5.1 on A2UI tells a regulated-enterprise team little about what their on-prem Llama-3, Qwen-3, or Gemma-4 will do with the same spec. The training data, the quantisation regime, and the in-context behaviour differ. Cloud numbers do not transfer to local production.
Third, direction of travel. Data sovereignty, cost predictability, regulatory compliance, and latency control push enterprise agentic work toward local inference. The benchmark should test the deployment surface that matters for production planning.
What the numbers actually say
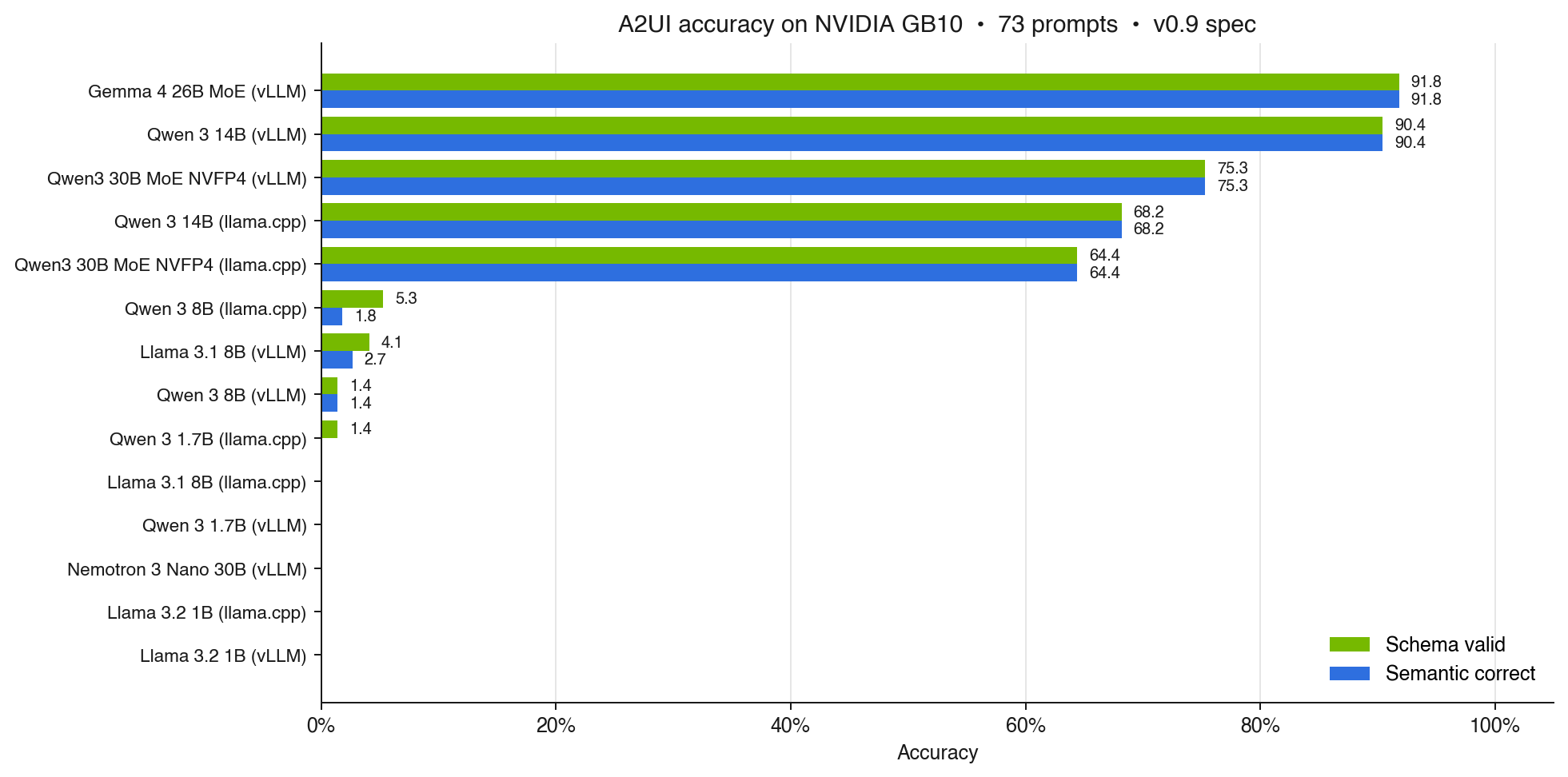
Time for the part you scrolled here for. The board, sorted by semantic accuracy:
| Model | Engine | Schema valid | Semantic |
|---|---|---|---|
| Gemma 4 26B MoE (NVFP4) | vLLM | 91.8% | 91.8% |
| Qwen 3 14B | vLLM | 90.4% | 90.4% |
| Qwen3 30B MoE NVFP4 | vLLM | 75.3% | 75.3% |
| Qwen 3 14B | llama.cpp | 68.2% | 68.2% |
| Qwen3 30B MoE NVFP4 | llama.cpp | 64.4% | 64.4% |
| Qwen 3 8B | llama.cpp | 5.3% | 1.8% |
| Llama 3.1 8B | vLLM | 4.1% | 2.7% |
| Qwen 3 8B | vLLM | 1.4% | 1.4% |
| Qwen 3 1.7B | llama.cpp | 1.4% | 0% |
Six additional configurations all scored 0%/0%: Qwen 3 1.7B on vLLM, Nemotron 3 Nano 30B on both engines, Llama 3.2 1B on both engines, and Llama 3.1 8B on llama.cpp. Full per-sample data is in the report linked at the end.
Two things jump out.
First, schema validity and semantic correctness move together almost perfectly. If a model produces a valid A2UI tree, it usually produces a sensible one. There is no big middle group of "valid JSON, wrong UI". The validator is the gate, and getting through the gate is the hard part.
Second, the engine moves accuracy more than "it is just a latency choice" suggests, but it does not flip a model out of its league. Qwen 3 14B scores 90.4% on vLLM and 68.2% on llama.cpp, a 22-point gap, but still the same league. Where the engine actually kills you is on models that are right at the edge: Qwen 3 8B is 5.3% on llama.cpp and 1.4% on vLLM, and the capability is not there in the first place. I will dig into the engine differences in a follow-up post.
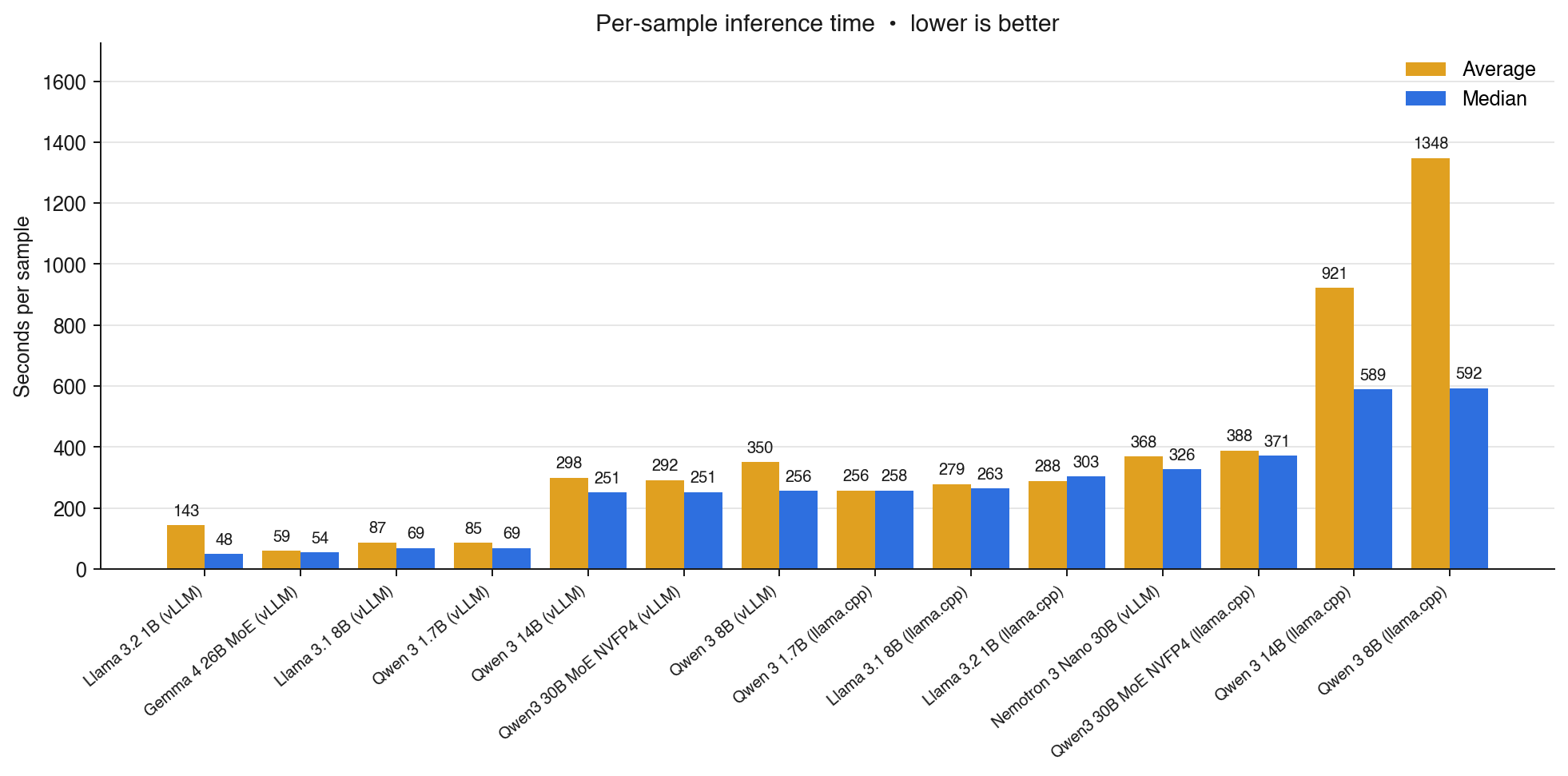
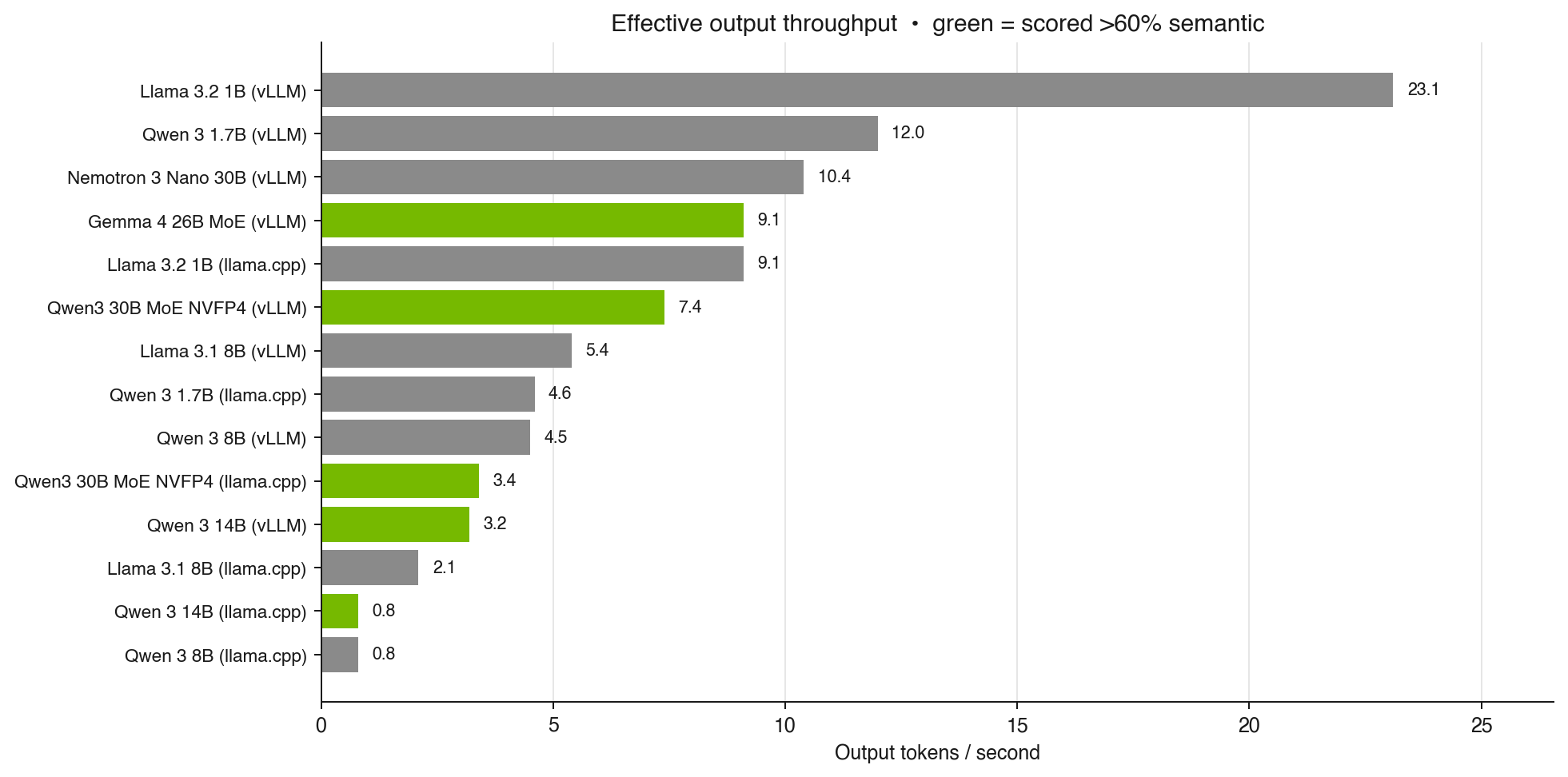
The actual winner on this hardware is the Gemma 4 26B MoE at NVFP4. It is also the fastest in the lineup, with about 59 seconds median per sample and 9.1 tokens/s of effective output throughput. MoE pays off on memory-bandwidth-limited hardware: fewer active parameters per token, same accuracy. That matters more for A2UI than for most workloads, because the generated payloads are long structured JSON trees and decode is bandwidth-bound for every one of those tokens.
The fun part: why small models score zero
The interesting story is not "the big models win". It is "the small models do not even get to play". When I dug into the per-sample rationales, the same phrase appears 73 times in a row: Schema validation failed; output is not a valid A2UI tree. That sounds like the model cannot do it. It is not what is happening.
The validator only accepts payloads wrapped in literal <a2ui-json>...</a2ui-json> tags. No markdown fence fallback, no automatic unwrap of "thinking" preambles, no acceptance of structurally valid JSON in any other envelope. Spot-checking the failures across the small-model rows shows the same pattern: the inputs were well under the 16k serving limit, the output cap was never hit, the JSON was often fine. The wrapper was wrong.
The cast of failure modes:
- Llama 3.2 1B politely emits a JSON Schema definition (
"$schema": "https://json-schema.org/...") describing what a Text component should look like, instead of an A2UI instance. No<a2ui-json>tags appear at all. The model understood the task as "describe", not "produce". - Qwen 3 1.7B uses the right tags but malforms the structure:
versionplaced insideupdateComponents, plus a duplicated nestedupdateComponentsblock. - Qwen 3 8B (vLLM) wraps otherwise-correct A2UI JSON in
```jsonmarkdown fences instead of<a2ui-json>tags. The content is largely valid. The validator says "tags not found" and the run scores near zero. This one hurts. - Nemotron 3 Nano 30B is a reasoning model and emits a
<think>...</think>preamble followed by the final answer. The final answer then double-wrapscreateSurfaceinside anothercreateSurface. The thinking was fine. The wrapping was not.
These are not capability ceilings. They are instruction-following and format-compliance gaps. A single follow-up turn, or a more lenient extractor that accepts any fenced JSON block whose root matches the A2UI message schema, would close most of these. The benchmark deliberately does not apply those fallbacks, so scores reflect what a renderer running the production parser would actually accept.
In production you would build the safety net. In the benchmark you measure the gap honestly.
I hope this gave you a clearer view of the A2UI behind the curtains. Questions? Email info@soverius.ai. For new essays and workshop announcements, use the "Stay Updated" form.

Comments
No comments yet. Be the first.